
We are constantly estimating and prioritizing our daily tasks from the moment we open our eyes. We always complete the important tasks first. But how do we determine which tasks need to be done first? For instance, saving someone’s life is more important than watching TV. So, if we have the option to choose between the two, which one should we pick first? When we consider the number of years needed to be qualified to save someone’s life as a doctor, watching an episode of a TV series right now might not appear that bad. So, it seems we always prioritize our tasks based on the benefit and the amount of time it takes to do it. When we invent a time machine, we will probably remove time from this equation, but until then, we need to consider it.
A simple formula for common sense
Let us look at an example to better understand the situation. If we have the following two tasks to pick from, which one would you complete first?
| Task A | Task B | |
|---|---|---|
| Profit | 15,000$ | 10,000$ |
| Duration | 5 days | 1 day |
Even though task A returns 5,000$ more profit than task B, but since task A takes 5 times longer than task B, it is best to complete task B first. We can determine which one needs to be done first using simple math:
Task A: 15,000$ / 5 days = 3,000$ per day < 10,000$ per day: Task B
We can determine which task needs to be done first by dividing the profit of completing the task over the effort needed to finish it.
Priority = Profit / Size
- Profit represents the value of completing the task.
- Size is the effort needed to complete the task.
- Higher Priority number means the task is more important.
The issue with using Time as a unit of measurement
Time is a common unit of measurement in estimation. In this approach, tasks sizes are estimated in days, hours or even weeks. The main challenge in using time as a unit of measurement is the expectation it brings with it. If a task is estimated to be completed in 1 day, it is often expected that the task will be done by tomorrow. After all, it is a small task.
We can agree this is mainly a communication issue. But can we avoid it? If we look carefully, we see the main issue here is using the same unit of measurement for estimating the size of a task (the effort needed to finish a task) and the time we can expect the task to be completed.
If we simply remove the word “day”, we can avoid the issue. When the effort needed to complete a task is estimated 20, there is no room left for assumptions! Because the next question has to be: “What does that even mean? Just tell me when it will be done!”. This way, the size of a task is not confused by its completion date.
Estimation accuracy
Since smaller tasks are simpler in nature, we can imagine them much better than bigger tasks. In other words, the accuracy of our estimations worsens as the sizes of our tasks grow. This means, if we estimate a big task to be 100, it will be very hard to argue why it is not 99.5. To make our life easier and avoid the long discussions about why a task should be 99.5 instead of 100, we could limit ourselves to fewer numbers.
One of the common sets used in estimation is the Fibonacci sequence. However, you can build your own set of numbers, if you wish, as long as the gap between the elements of the set increases. Why not give Y = X2 a try!
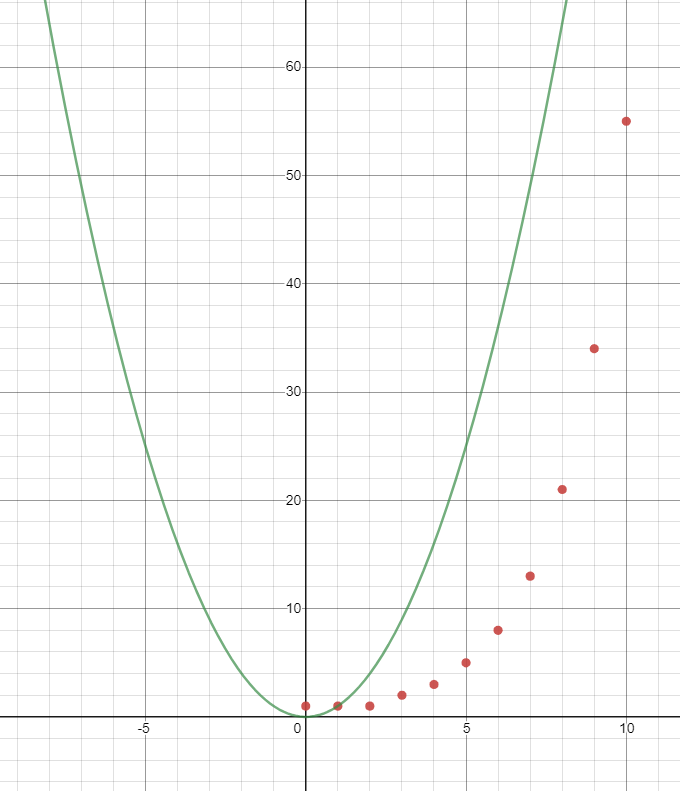
How to estimate tasks using Relative sizing?
In this approach, as the name suggest, we use comparison to determine the size of the tasks and assign a number to them. Regardless of which number set we use in our estimation, the following steps still apply. This approach is helpful if we are working with a newly constructed team.
- Build a benchmark list. Go through some of the team’s completed tasks and make a list. The list must:
- Include a good mixture of small and big tasks.
- Include known tasks. It is important that everyone understands the tasks and they can relate to the tasks.
- Sort the list of tasks by comparing the tasks sizes with each other.
- Assign numbers to the benchmark list. Assign numbers from an estimation number set (Fibonacci sequence for example) to the tasks. In the example below, as you can see, the effort needed to “Do my laundry” is estimated to be 8.

From now on, we can use the benchmark list in our estimations. Take any task and compare them with each of the tasks in the benchmark list. Rounding up the estimations might be a good idea if we find out the effort needed to complete a task falls in between two tasks in the benchmark list. For example, “taking my car to a car wash” falls in between “Do my laundry” and “Finish my article” in the example above. By rounding up, we assign the number 13 to “taking my car to a car wash” task.
In our earlier example, we estimated the value of completing a task in dollars. However, we can apply the same approach and use relative sizing to estimate the tasks profits. Now, we have our backlog ready. The most important tasks with higher Priority will be on top of the backlog.
Tiebreaker
We can easily get into a situation where two tasks have the same Priority values. We cannot completely avoid this issue. However, we can introduce a tiebreaker in our system that only applies to the set of tasks with the same Priority number:
Priority’ = Priority – Size
This formula puts the tasks that take less time to finish at the top of the list of tasks with the same Priority number. In the example below, tiebreaker formula helps us with prioritization of task A and task B. However, it does not help determine whether we should work on task C or task D first.
| Task | Profit | Size | Priority | Priority’ |
| C | 200 | 50 | 200/50 = 4 | Won’t help |
| D | 200 | 50 | 200/50 = 4 | Won’t help |
| A | 10 | 5 | 10/5 = 2 | 2 – 5 = -3 |
| B | 20 | 10 | 20/10 = 2 | 2 – 10 = -8 |
| E | 15 | 15 | 15/15 = 1 | Not needed |
You could use the following formula as an alternative, if you wish to focus on the tasks with the most Profit value first when time is not an issue:
Priority’ = Priority + Profit
What to include in our estimations?
Let us assume we have a task to copy the content of a file to another one. We can finish the task by copy pasting every single line manually. This is a simple task with low complexity, but it will take a long time to finish. So, complexity alone cannot be a factor.
Another common factor used in estimation is the level of uncertainty. How can you quantify your uncertainty? How is 80% uncertainty different from 79%? This is a distraction which we can easily avoid.
Instead of introducing multiple variables when working with uncertainties, it is best to combine them all as one for simplicity purposes. Also, we need to consider the approach we are going to take before we start the estimation process. The effort required to complete a task, just like the example above, can be very different depending on which solution we decide to use. So, make sure to understand the expectations of the task and complete any Proof of Concepts (COP) first.
How much analysis is enough?
In the prioritization process, we prepared a sorted list of tasks based on the effort needed to complete them by simply comparing them to one another. That means, we can stop wasting time on finding all the details as long as we are confident that the position of the item we are currently estimating won’t change in relation to other tasks. This can be very helpful if the gap between the task sizes are big.
Who should participate in estimation?
It is very common that the initial (quick and dirty) estimates are done by subject matter experts in certain area. And when the prioritization is done, the task is passed to a team with an expected deadline. If the team disagrees with the initial estimates, the team estimates the task once more. If a team does not update the estimate again, then the team might not work on the most important tasks since the cost of a task affects its priority.
A better solution is to ask subject matter experts to help the teams understand the tasks better instead of providing an estimate themselves. After all, the team is the one completing the tasks.
How to determine when a task is done?
By looking at how fast a team delivers a group of tasks, we can estimate the completion date of a task no matter what unit of measurement we end up using. The speed of task delivery can be calculated for any team using the following formula:
Velocity = The sum of completed tasks sizes / Time taken to finish the tasks
A team’s velocity can be 20 per week. This means if they estimate a task to be 40, it will take them 2 weeks to complete it.
Since the team dynamic changes over time, it is a good idea to use moving average of the team velocity instead.
We can measure each individual delivery speed if we have a group of people. However, since everyone in a team works toward the same goal, a single velocity value to represent the whole team should be sufficient.
Multiple teams
If you find yourself in a situation where every team is using their own numeric unit of measurements, you need to find an exchange rate to be able to translate one to another.
Building a benchmark list for a bigger audience helps us with the conversion ratio. To do so, you need to give each team the same task (or very similar tasks) and measure the speed of their deliveries over a fixed period of time. You can now convert one unit to another since we fixed both variables, Time and Size. If this is not possible, avoid comparing the teams’ velocities.
Conclusion
We learned how to simplify estimation and prioritization process by focusing on what really matters and avoid measuring uncertainties accurately.




Two points from my experience ( with scrum backlogs). First the value of a task depends which stakeholder is valuing it. A business product owner may have a different value to a project implementer. Second, usually those estimating effort tend to continue with the same bias (error) regardless of the progression used fib or square law etc). So I find it best to stick with one of these and apply a correction based on results to date.